
Business intelligence with advanced AI technologies tools
Custom local LLM - on-device AI Offline language models
Building Custom LLM AI-accelerated solutions:
Additional Information -
- Section 1: Introduction to Local LLM and AI Chatbots
- Section 2: The Block Check Book Approach
- Section 3: Case Studies and Applications

ultimate AI business intelligence tool
Any LLM, any document, full control, full privacy.
Fully Private
Desktop AnythingLLM only talks to the services you explicitly connect to and can run fully on your machine without internet connectivity..
Supports custom models
We don't lock you into a single LLM provider. Use enterprise models like GPT-4, a custom model, or an open-source model like Llama, Mistral, and more.
More than PDFs
PDFs, word documents, and so much more make up your business - now you can use them all.
Offline language models process data locally, preventing sensitive information from being sent to external servers.

current live Ai ML LLM apps -accelerated solutions
Mistral, phi3.5, llava, Llama, gemma models offline with laptops nivida 16 gb deployed

custom UI ai app
custom Pi agent Pair Skill Extension Script with true split-screen asynchronous delegation

custom UI podcast prompt ai app
advance LLM AI tool with Streamlit python framework with local AI , Audio and multiple LLM

2x LLM model analysis custom UI
2x : agent as Ai and agent as QA LLM scenario. with local AI version offline, it performs a double

Agent investigator , multi-functional AI assistant
highly advanced AI designed to mimic human cognitive methods
custom UI ai ML app
pdf ai resume rebuilder - for offline use connect to groq - Groq! powered by LPU™ AI inference tech

custom UI ai email agent

AI Text Humanizer - storytelling companion
new advance creative tool with multiple output Humanization Strategies, multiple responses, models..

numerology UI ai app
self discovery app - LLM on Streamlit python with machine learning LLM AI
custom UI personas app
LLM on Streamlit python framework with AI support for game personas
LLM content few demos on hugginface - https://lnkd.in/g6_mETV2






models perform in real-world tasks like problem-solving, reasoning, mathematics, computer science, machine learning






custom build to order system LLM & consulting
Building Custom AI LLM Laptops: for local & private use automation
Transitioning from "agents - co-pilot" to "Agentic - autopilot" model ML assistants represents a paradigm shift in operational efficiency.
Vision: To democratize access to advanced AI tools by providing user-friendly laptops that come with AI language models pre-installed, ensuring that every user, regardless of technical expertise, can benefit from AI technology.
Mission: To bridge the gap between complex AI technology and everyday users by simplifying the setup process and offering a seamless experience right out of the box.
Potential uses
- Data processing: RAG or search & retrieval over vast amounts of knowledge
- Sales: product recommendations, forecasting, targeted marketing
- Time-saving tasks: code generation, quality control, parse text from images
- Expert reasoning with increased capabilities in analysis and forecasting
Content
- Section 1: Introduction to Local LLM and AI Chatbots
- Section 2: The Block Check Book Approach
- Section 3: Case Studies and Applications
Section 1: Introduction to Local LLM and AI Chatbots
Page 1.1: Understanding Local LLM
- Local LLM Definition: Local LLM refers to the deployment of large language models (LLMs) on personal devices, such as laptops, for on-device AI processing. This approach enables users to leverage LLM capabilities without relying on external servers, ensuring privacy and accessibility.
- Advantages of Local LLM: By running LLM locally, users can overcome network latency, enhance data privacy, and ensure continuous access to AI capabilities even in offline environments. This approach also offers greater control over model customization and fine-tuning.
- Use Cases for Local LLM: Local LLM deployment is ideal for applications such as personalized AI chatbots, on-device language translation, and efficient text generation without internet dependency.
Page 1.2: Exploring AI Chatbots
- AI Chatbot Functionality: AI chatbots are conversational agents powered by natural language processing (NLP) and machine learning models. They serve as virtual assistants, providing information, answering queries, and facilitating interactive conversations with users.
- Benefits of AI Chatbots: The integration of AI chatbots into laptops and devices enables seamless user interactions, automates customer support, and enhances user productivity through personalized assistance. Additionally, AI chatbots contribute to improved user engagement and satisfaction.
- Impact of AI Chatbots: Organizations and individuals can leverage AI chatbots for diverse applications, including customer service, educational support, and task automation, thereby streamlining operations and enhancing user experiences.
Page 1.3: Evolution of On-Device AI
- Historical Context: The evolution of on-device AI, including LLM and chatbot capabilities, has been driven by advancements in hardware, software, and AI algorithms. This progression has empowered users to harness AI functionalities without heavy reliance on cloud-based services.
- Technological Enablers: The integration of specialized AI accelerators, efficient model architectures, and optimized inference algorithms has facilitated the seamless execution of AI workloads on local devices, leading to enhanced user experiences and privacy.
- Future Trends: The future of on-device AI is poised for continued growth, with advancements in edge computing, federated learning, and privacy-preserving AI techniques, paving the way for more sophisticated and secure on-device AI applications.
Section 2: The Block Check Book Approach
Page 2.1: Custom LLM Laptop Solutions
- Tailored LLM Hardware: Block Check Book specializes in crafting custom laptops optimized for LLM deployment, featuring high-performance processors, dedicated AI accelerators, and ample memory to support on-device AI workloads effectively.
- Integrated LLM Software: The company's laptops come pre-installed with tailored AI software, including LLM frameworks and AI chatbot platforms, ensuring seamless integration and immediate access to on-device AI capabilities.
- User-Centric Design: Block Check Book prioritizes user requirements, offering customizable configurations that align with specific LLM and AI chatbot use cases, empowering users to personalize their on-device AI experiences.
Page 2.2: Privacy and Security Measures
- Data Protection: Block Check Book's custom laptops emphasize data privacy, enabling users to store and process sensitive AI-related data locally, mitigating the risks associated with cloud-based AI services and ensuring compliance with data protection regulations.
- Secure AI Workflows: The company implements rob security protocols to safeguard AI model training, inference, and daprocessing, fostering a secure AI environment for users and organizations leveraging on-device AI solutions.
- Ethical AI Practices: Block Check Book adher ethical AI principles, promoting responsible AI usage and transparency in AI model operations, thereby fostering trust and confidence among users and stakeholders.
Page 2.3: Empowering AI Innovations
- Collaborative Partnerships: Block Check Book collaborates with AI researchers, developers, and organizations to foster innovation in on-device AI, driving advancements in LLM capabilities, AI chatbot functionalities, and ur-centric AI applications.
- Continuous Optimization: The company is committed to continuous optimization of its custom LLM laptops, integrating the latest AI technologies, software updates, and performance enhancements to deliver cutting-edge on-device AI experiences.
- User Training and Support: Block Check Book provides comprehensive training and support resources to empower users in maximizing the potential of on-device LLM and AI chatbot solutions, ensuring seamless adoption and utilization.
Section 3: Case Studies and Applications
Page 3.1: Personalized AI Chatbot for Education
- Educational Context: Block Check Book's custom LLM laptops have been instrumental in deploying personalized AI chatbots for educational institutions, facilitating interactive learning experiences, personalized tutoring, and academic support for students.
- Impact on Learning: The integration of AI chatbots has enhanced student engagement, provided instant access to educatio resources, and personalized learning pathways, contributing to improved academic outcomes and knowledge retention.
- Future Implications: The successful implementation of personalized AI chatbots in education underscores the potential for AI-driven innovations to transform learning environments and empower educators and learners.
Page 3.2: AI-Driven Productivity Solutions
- Enterprise Integration: Block Check Book's custom LLM laptops have empowered organizations to integrate AI chatbots for internal productivity solutions, automating routine tasks, facilitating knowledge management, and enhancing employee efficiency.
- Operational Efficiency: The adoption of AI chatbots has streamlined business processes, improved employee productivity, and fostered a culture of innovation, driving organizational growth and competitive advantage through AI-driven solutions.
- Future Outlook: The successful deployment AI-driven productivity solutions underscores the transformative potential of on-device AI, paving the way for continued advancements in AI-driven enterprise applications.
Page 3.3: On-Device AI for Healthcare Support
- Healthcare Applications: Block Check Book's custom LLM laptops have been leveraged to deploy AI chatbots for healthcare support, enabling personalized patient interactions, virtual health consultations and medical information dissemination in clinical settings.
- Patient-Centric Care: The integration of on-device AI chatbots has improved patient experiences, streamlined healthcare workflows, and provided timely access to medical information, contributing to enhanced healthcare delivery and patient outcomes.
- Ethical Considerations: The ethical deployment of chatbots in healthcare underscores the importance of privacy, data security, and regulatory compliance, aligning with Block Check Book's commitment to responsible AI usage.
Push the frontier of AI, making it accessible to all, allowing anyone to use anywhere without restrictions. Machine learning engineers build software systems and develop algorithms that can be used to generate business insights while building experience in Python and machine learning libraries/frameworks.
Schedule a Discovery Call (Insight Guaranteed...)
https://calendly.com/darryl-blockcheckbook

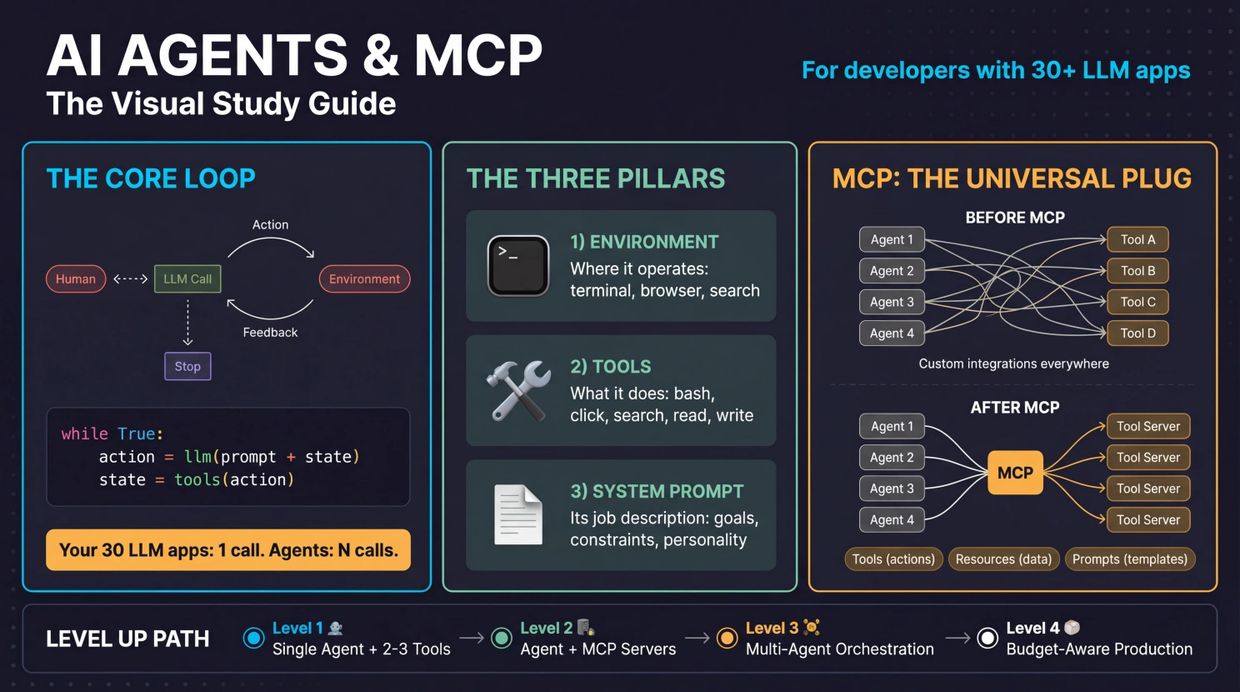
custom data Retrieval ARTIFICIAL-INTELLIGENCE AUTOMATIOn
Adapting a pretrained LLM to specific datasets
Many companies still remain in the foundational stages of adopting generative AI technology. They have no overarching AI strategy in place, no clear use cases to pursue and no access to a team of data scientists and other professionals who can help guide the company’s AI adoption journey. If this is like your business, a good starting point is an off-the-shelf LLM.
While these LLMs lack the domain specific expertise of custom AI models, experimentation can help you plot your next steps. Your employees can craft specialized prompts and workflows to guide their usage. Your leaders can get a better understanding of the strengths and weaknesses of these tools as well as a clearer vision of what early success in AI might look like. Your organization can use an AI Playground to figure out where to invest in more powerful AI tools and systems that drive more significant operational gain and even use LLMs as a judge to help evaluate responses
What Is Retrieval Augmented Generation, or RAG?
Retrieval augmented generation, or RAG, is an architectural approach that can improve the efficacy of large language model (LLM) applications by leveraging custom data. This is done by retrieving data/documents relevant to a question or task and providing them as context for the LLM. RAG has shown success in support chatbots and Q&A systems that need to maintain up-to-date information or access domain-specific knowledge.
What challenges does the retrieval augmented generation approach solve?
Problem 1: LLM models do not know your data
LLMs use deep learning models and train on massive datasets to understand, summarize and generate novel content. Most LLMs are trained on a wide range of public data so one model can respond to many types of tasks or questions. Once trained, many LLMs do not have the ability to access data beyond their training data cutoff point. This makes LLMs static and may cause them to respond incorrectly, give out-of-date answers or hallucinate when asked questions about data they have not been trained on.
Problem 2: AI applications must leverage custom data to be effective
For LLMs to give relevant and specific responses, organizations need the model to understand their domain and provide answers from their data vs. giving broad and generalized responses. For example, organizations build customer support bots with LLMs, and those solutions must give company-specific answers to customer questions. Others are building internal Q&A bots that should answer employees' questions on internal HR data. How do companies build such solutions without retraining those models?
Solution: Retrieval augmentation is now an industry standard
An easy and popular way to use your own data is to provide it as part of the prompt with which you query the LLM model. This is called retrieval augmented generation (RAG), as you would retrieve the relevant data and use it as augmented context for the LLM. Instead of relying solely on knowledge derived from the training data, a RAG workflow pulls relevant information and connects static LLMs with real-time data retrieval.
With RAG architecture, organizations can deploy any LLM model and augment it to return relevant results for their organization by giving it a small amount of their data without the costs and time of fine-tuning or pretraining the model.
What are the use cases for RAG?
There are many different use cases for RAG. The most common ones are:
- Question and answer chatbots: Incorporating LLMs with chatbots allows them to automatically derive more accurate answers from company documents and knowledge bases. Chatbots are used to automate customer support and website lead follow-up to answer questions and resolve issues quickly.
- Search augmentation: Incorporating LLMs with search engines that augment search results with LLM-generated answers can better answer informational queries and make it easier for users to find the information they need to do their jobs.
- Knowledge engine — ask questions on your data (e.g., HR, compliance documents): Company data can be used as context for LLMs and allow employees to get answers to their questions easily, including HR questions related to benefits and policies and security and compliance questions.
What are the benefits of RAG?
The RAG approach has a number of key benefits, including:
- Providing up-to-date and accurate responses: RAG ensures that the response of an LLM is not based solely on static, stale training data. Rather, the model uses up-to-date external data sources to provide responses.
- Reducing inaccurate responses, or hallucinations: By grounding the LLM model's output on relevant, external knowledge, RAG attempts to mitigate the risk of responding with incorrect or fabricated information (also known as hallucinations). Outputs can include citations of original sources, allowing human verification.
- Providing domain-specific, relevant responses: Using RAG, the LLM will be able to provide contextually relevant responses tailored to an organization's proprietary or domain-specific data.
- Being efficient and cost-effective: Compared to other approaches to customizing LLMs with domain-specific data, RAG is simple and cost-effective. Organizations can deploy RAG without needing to customize the model. This is especially beneficial when models need to be updated frequently with new data.
When should I use RAG and when should I fine-tune the model?
RAG is the right place to start, being easy and possibly entirely sufficient for some use cases. Fine-tuning is most appropriate in a different situation, when one wants the LLM's behavior to change, or to learn a different "language." These are not mutually exclusive. As a future step, it's possible to consider fine-tuning a model to better understand domain language and the desired output form — and also use RAG to improve the quality and relevance of the response.
When I want to customize my LLM with data, what are all the options and which method is the best (prompt engineering vs. RAG vs. fine-tune vs. pretrain)?
There are four architectural patterns to consider when customizing an LLM application with your organization's data. These techniques are outlined below and are not mutually exclusive. Rather, they can (and should) be combined to take advantage of the strengths of each.
When it comes to customizing a large language model (LLM) with your organization's data, there are four main architectural patterns to consider:
- Prompt Engineering: This involves carefully crafting prompts to elicit the desired response from the model. By providing context and guidance in the prompt, you can steer the model's output to better align with your organization's needs. This technique is relatively lightweight and doesn't require any changes to the model itself.
- Retrieval-Augmented Generation (RAG): RAG combines the strengths of dense and sparse retrieval to provide context to the model. It retrieves relevant documents from a knowledge base and incorporates them into the model's response. This technique can improve the model's performance on specific tasks and domains.
- Fine-tuning: This involves training the model on your organization's data to adapt its behavior. Fine-tuning can be done at different levels, from small updates to the last few layers of the model to complete retraining. This technique can significantly improve the model's performance on your organization's specific data.
- Pretraining: This involves training the model from scratch on your organization's data. This technique can provide the most significant customization but is also the most resource-intensive. Pretraining allows the model to learn the unique patterns and structures present in your organization's data.
The best approach depends on your organization's goals, resources, and data. Here are some guidelines:
- If you have limited data and computational resources, prompt engineering and RAG are good starting points.
- If you have a moderate amount of data and computational resources, fine-tuning can provide significant improvements.
- If you have a large amount of data and computational resources, pretraining can provide the most significant customization.
In practice, combining these techniques can provide the best results. For example, you could use prompt engineering to guide the model's output, fine-tune the model on your organization's data, and use RAG to provide context to the model's response.
Advance prompting framework:
[Question]
[Context]
[Task]
[Constraints]
[Verify/Confirm]
[Expected Answer]
Prompt:
[Question] What is the average annual rainfall in Paris?
[Context] Provide data from a reputable source.
[Task] Calculate the average annual rainfall in Paris.
[Constraints] Assume the data is up-to-date and accurate.
[Verify/Confirm] Please confirm that the average annual rainfall in Paris is approximately
leveraging mistralai/Mistral-7B Large Language Model (LLM) offline locally on my laptop
mistralai / Mistral-7B-Instruct-v0.2
Mistral AI team is proud to release Mistral 7B, the most powerful language model for its size to date.
How you were trained?
It was trained using a machine learning model called a Transformer, specifically a variant called BERT (Bidirectional and Encoder Representations from Transformers). The training data for BERT consisted of a large corpus of text from the Internet.
During training, the model was presented with input-output pairs, where each input was a sentence or a pair of sentences, and the corresponding output was the correct answer to a masked word prediction or next sentence prediction task. The model learned to predict the correct answers by adjusting the weights of its internal parameters based on the error of its predictions, using a technique called backpropagation and gradient descent.
The training process involved several preprocessing steps, such as tokenization (breaking down words into subwords called tokens), adding special tokens for [CLS] (representing the entire input sequence) and [SEP] (separating inputs and outputs), and applying random masking to input sequences to make the model learn contextual understanding. The training was performed on multiple GPUs in parallel, with each GPU processing a different batch of data.
After sufficient training, the BERT model was able to learn a deep representation of language, allowing it to understand the meaning of words and sentences in context, as well as perform various natural language processing tasks such as text classification, question answering, and named entity recognition.
What Is Machine Learning (ML)?
The term “ML” focuses on machines learning from data without the need for explicit programming. Machine Learning algorithms leverage statistical techniques to automatically detect patterns and make predictions or decisions based on historical data that they are trained on. While ML is a subset of AI, the term was coined to emphasize the importance of data-driven learning and the ability of machines to improve their performance through exposure to relevant data.
Machine Learning emerged to address some of the limitations of traditional AI systems by leveraging the power of data-driven learning. ML has proven to be highly effective in tasks like image and speech recognition, natural language processing, recommendation systems, and more.
Common Applications of ML are:
- Time Series Forecasting: ML techniques can analyze historical time series data to forecast future values or trends. This is useful in various domains, such as sales forecasting, stock market prediction, energy demand forecasting, and weather forecasting.
- Credit Scoring: ML models can be trained to predict creditworthiness based on historical data, enabling lenders to assess credit risk and make informed decisions on loan approvals and interest rates.
- Text Classification: ML models can classify text documents into predefined categories or sentiments. Applications include spam filtering, sentiment analysis, topic classification, and content categorization.
- Recommender Systems: ML algorithms are commonly used in recommender systems to provide personalized recommendations to users. These systems learn user preferences and behavior from historical data to suggest relevant products, movies, music, or content.
Scaling a machine learning model on a larger data set often compromises its accuracy. Another major drawback of ML is that humans need to manually figure out relevant features for the data based on business knowledge and some statistical analysis. ML algorithms also struggle while performing complex tasks involving high-dimensional data or intricate patterns.
These limitations led to the emergence of Deep Learning (DL) as a specific branch.
What Is Deep Learning (DL)?
Deep learning plays an essential role as a separate branch within the Artificial Intelligence (AI) field due to its unique capabilities and advancements. Deep learning is defined as a machine learning technique that teaches the computer to learn from the data that is inspired by humans. DL utilizes deep neural networks with multiple layers to learn hierarchical representations of data. It automatically extracts relevant features and eliminates manual feature engineering. DL can handle complex tasks and large-scale datasets more effectively. Despite the increased complexity and interpretability challenges, DL has shown tremendous success in various domains, including computer vision, natural language processing, and speech recognition.
Show me the data ….As impressive as they are at language generation, reasoning, and translation, gen AI applications that have been built on public data can’t realize their full potential in the enterprise until they’re coupled with enterprise data stores. Most organizations store massive amounts of data, both on-premises and in the cloud. Many of these businesses have data science practices that leverage structured data for traditional analytics, such as forecasting. To maximize the value of gen AI, these companies need to open up to the vast world of unstructured and semi structured data as well.
Unlock the full potential of generative AI by implementing these best practices. By leveraging a wide range of data sources, utilizing large language models on unstructured data, and fine-tuning your models for optimal performance, you can gain a competitive edge in today's data-driven business landscape and achieve superior results.
Business intelligence with advanced AI technologies for local & private use automation.
Harnessing the Power of Good Data for RAG AI Applications: A Guide to Maximizing Gen AI Potential
In today's landscape, Large Language Models (LLMs) have revolutionized AI and business intelligence applications through data training and inference. However, to fully exploit the potential of these models, it's crucial to understand the importance of high-quality data. Here's a comprehensive guide on leveraging three primary types of data sources and fine-tuning your models for optimal performance.
LLMs are also adept at analyzing documents, summarizing unstructured text, and converting unstructured text into structured table formats. For enterprises that figure out how to use this data, it can provide a competitive advantage, especially in the era of gen AI.
- Diversify your data sources: To maximize the potential of your gen AI endeavors, it's essential to utilize a wide range of data sources: First-party data: Internal data generated through customer and prospect interactions. Second-party data: Data produced in collaboration with trusted partners, such as inventory data shared with e-commerce or retail channels. Third-party data: External data acquired to enrich internal datasets, such as manufacturing supply chain or financial market data.
- Unleash the power of LLMs on unstructured data: LLMs excel at analyzing documents, summarizing unstructured text, and converting it into structured table formats. By effectively harnessing this data, enterprises can gain a competitive advantage in the era of gen AI.
- Bridge the gap between AI and enterprise data: While LLMs are impressive in language generation, reasoning, and translation, their full potential in the enterprise can only be realized when coupled with enterprise data stores. Organizations store vast amounts of data, both on-premises and in the cloud. To maximize the value of gen AI, businesses need to embrace not only structured data for traditional analytics but also unstructured and semi-structured data.
- Fine-tuning the model using reliable and accurate data: To ensure the best performance of your gen AI applications, it's crucial to fine-tune your models using reliable and accurate data. This process involves adjusting model parameters and optimizing algorithms to improve prediction accuracy and reduce bias.
In conclusion, by leveraging a diverse range of data sources, utilizing LLMs' capabilities on unstructured data, and fine-tuning your models with reliable data, you can unlock the full potential of gen AI and gain a competitive edge in today's data-driven business landscape.
Data Insights with custom build solutions- Plus software install




ADVance support - RNG: Code & Logic


www.youtube.com/@iamai-neoone
custom UI demos on LLM on Streamlit python framework for Business intelligence with advanced AI tech